PostgreSQL offers a simple method to partition table spaces into smaller spaces based on table inheritance. What this means is that while you logically still have one table (Say 'cities'), it is physically divided into several tables (cities~usa~, cities~spain~, cities~germany~, etc). This allows PostgreSQL to distribute database load to multiple tables instead of just one. You will just use the 'cities' table in your queries, but internally PostgreSQL will use the 'cities~germany~' or 'cities~spain~' table instead.
Let's imagine a cities{.verbatim} table as explained above, with one
field, the city's name1.
INSERT INTO cities (name) VALUES ('San Francisco');
INSERT INTO cities (name) VALUES ('Los Angeles');
INSERT INTO cities (name) VALUES ('Berlin');
INSERT INTO cities (name) VALUES ('Barcelona');
SELECT name FROM cities;
=> ('San Francisco', 'Los Angeles', 'Berlin', 'Barcelona')
SELECT name FROM cities_usa;
=> ('San Francisco', 'Los Angeles')
SELECT name FROM cities_germany;
=> ('Berlin)
Why would you do something like that? Well, this has several advantages, as the PostgreSQL documentation points out:
Query performance can be improved dramatically in certain situations, particularly when most of the heavily accessed rows of the table are in a single partition or a small number of partitions. The partitioning substitutes for leading columns of indexes, reducing index size and making it more likely that the heavily-used parts of the indexes fit in memory.
When queries or updates access a large percentage of a single partition, performance can be improved by taking advantage of sequential scan of that partition instead of using an index and random access reads scattered across the whole table.
Bulk loads and deletes can be accomplished by adding or removing partitions, if that requirement is planned into the partitioning design. ALTER TABLE NO INHERIT and DROP TABLE are both far faster than a bulk operation. These commands also entirely avoid the VACUUM overhead caused by a bulk DELETE.
Seldom-used data can be migrated to cheaper and slower storage media.
One advantage of the inheritance based approach is that if you need to define an additional field, you can just do it on the master table and PostgreSQL will automatically provide the field on the partitioned tables. Even auto incremented ids work.
I'm currently working on a system where a huge amount of URLs will be
stored in PostgreSQL tables. As the main operation on these entities
will be UPDATE{.verbatim}, INSERT{.verbatim} and
SELECT{.verbatim}, it makes sense to distribute the locking load to
more than one physical entity.
The question I asked myself was, which partitioning scheme is useful for URLs?
Getting a Sample Dataset
I decided to approach this problem empirically. I wrote a small clojure script that scans Alexa.com and returns the most visited URLs for the following categories:
| Adult Arts Business Computers Games Health Home Kids~andTeens~ News Recreation Reference Regional Science Shopping Society Sports World
Doing this is really easy in Clojure. I just needed to go through all
the URLs and for each URL go through the pages 0 to 20. The gist of the
script is the following defn{.verbatim} which uses
Enlive to select the desired content
from the URL data and return it as a string:
This resulted in a sample of 8000 URLs which I then analyzed in Clojure to find a good partitioning algorithm.
Finding a Partitioning Algorithm
Group-By is a beautiful Clojure function which takes a collection and groups it into a map of results based on a grouping function:
=> {false [0 2 4 6 8], true [1 3 5 7 9]}
With that in mind, I just needed a function that would take a URL and return a useful grouping indicator for it. Since I wanted to compare several grouping functions, I implemented a function (based on Incanter) that would display the resulting partitioning:
The actual grouping function that implements the various analysis methods for grouping is rather simple. There're only two functions that need to be explained.
get-tld-value{.verbatim} Returns the tld (i.e. .de, .org, .com)cleanse-url{.verbatim} Removes regularities like http, www, m., etc.
As you can see, I implemented a couple of different comparison functions. Let's see what this resulted in.
Results of Grouping
Once we generated a groupting dataset, we can simply display it right from within Emacs (my Clojure working environment) with a call to view from the REPL:
=>
:domain
This was the first Idea I had: Grouping based on the tld (i.e. de, com, org), but the results were grossly distorted 2:
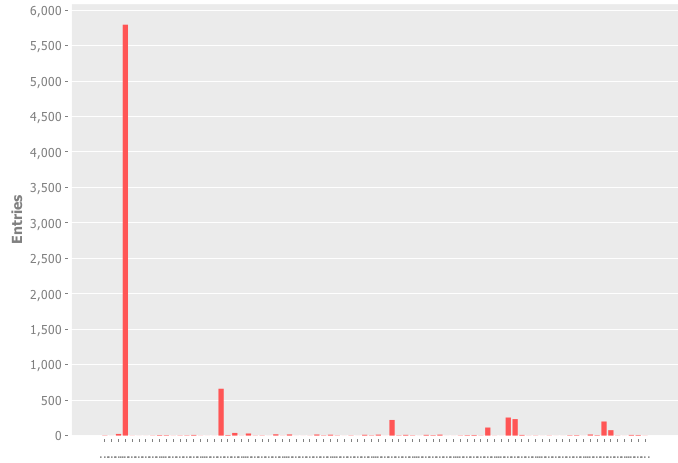
This was not usable because the one .com domain was so strong that I'd need to find additional indicators for proper partioning.
:length
The next thing I decided to try was the length of the host + tld. This was actually an interesting result because it looks a lot like a normal distribution.
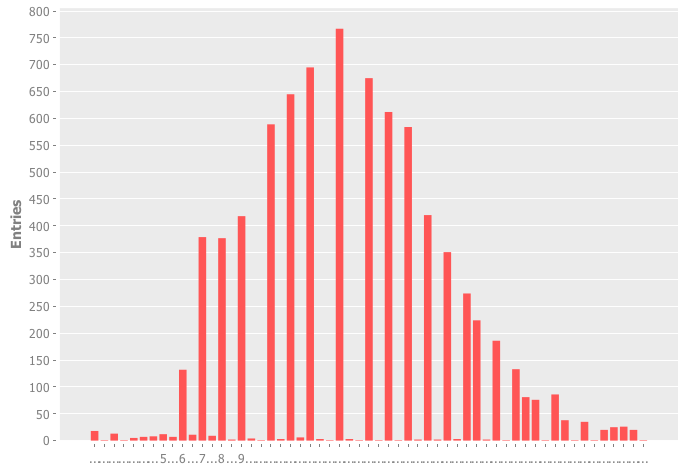
:length4
I wondered if the previous result could be minimzed to return less partitions as I'd rather not set up 50 partitions for a table, So I divided the result by 4.
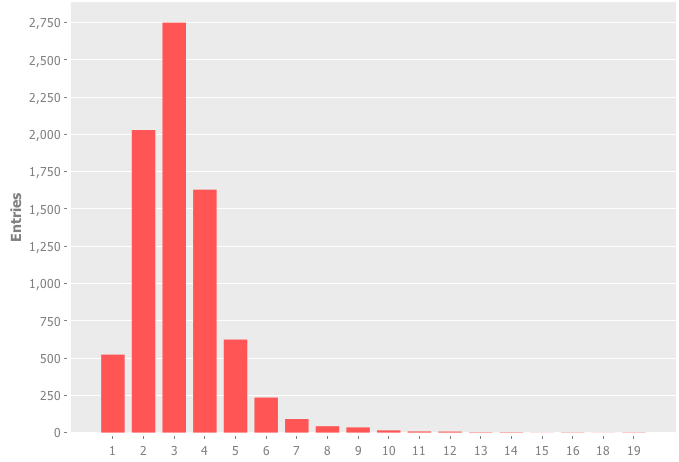
As you can see, this resulted in a much nicer distribution. By combining some of these groups, one could have a very uniform partitioning scheme. However if I try to add them to reach same-sized partitions, I would only end up with 3-4 partitions, which would not be enough.
:first
Next up, I decided to partition based on the first letter of the URL (this is something I found particularly interesting anyway and it was just one additional line of code to try it out):
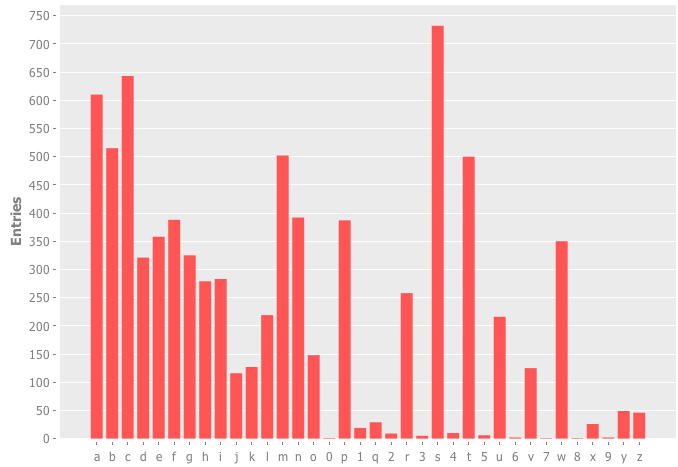
Can you see how strong some letters are against others? Particularly x, y, z, q, o, j and k have very few domains at their disposal, it seems. Sadly, this distribution is also not usable for partitioning, as it has strong differences and would require too many tables.
:firstbucket
Based on these results, I wondered what would happen if I would combine some letters into letter sets and group on these sets of letters.
So I wrote a simple Clojure function to use pattern matches to group the first letter3.
In this code, the line (re-find #"[bl]" c 1){.verbatim} means if the
variable c (which is the first character of our input string) is either
b or l, return 1.
So what happens when we try out this partitioning scheme?
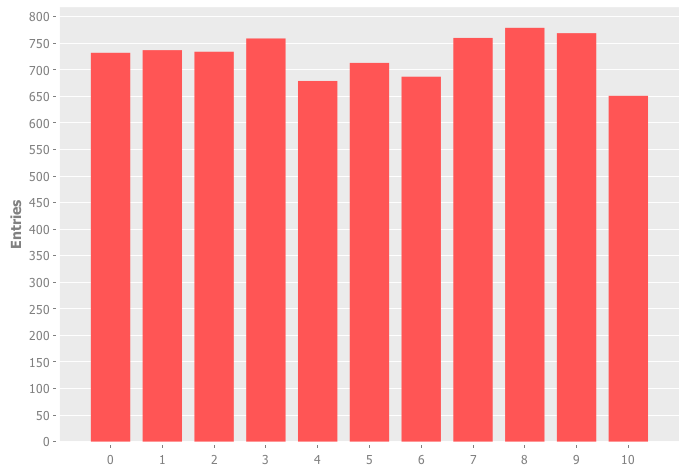
This result looks nice. As you can see I would end up with 10 partitions, each very close to each other. It may change if I take more international domains into account, but since the code exists in a simple Clojure project I can easily search more domains and see if my assumptions still hold up.
Implementing it in PostgreSQL
So the next, and final step is to take this partitioning theme and implement it in PostgreSQL. Table partitions are always based on a master table from which the partitions will inherit. For our example, the master table looks simple4:
(
url_id bigserial NOT NULL,
url character varying,
CONSTRAINT url_pk PRIMARY KEY (url_id)
);
After that, we want to create our partitioning tables for each of our url first letter sets:
( ) INHERITS (urls);
( ) INHERITS (urls);
...
( ) INHERITS (urls);
But... how do we define which items go into which of these sub-tables? We could of course just do that prior to inserting them in our code, but where would be the advantage of that compared to implementing the partitioning all on our own? Wouldn't it be nicer if PostgreSQL could take care of this? And in fact it does: Using constraints and functions, we can tell PostgreSQL what to put into which of these tables.
- Constraints: Are limits on tables that define what is allowed to go into a table. If we have an integer field 'max' on a table, and a constraint like = > 10 = then PostgreSQL would not allow us to insert anything into the table where the value of max is below 10.
- Functions: Functions are small snippets of code that PostgreSQL executes automatically upon certain actions like inserting or updating.
In order to implement the above scheme, we simply need to tell
PostgreSQL which characters are allowed. Fortunately, PostgreSQL offers
the ascii{.verbatim} function, which returns the Ascii value of the
first character of the argumen (i.e. the string). For the sake of
simplicity, we will ignore the fact that we have to remove
http://{.verbatim}, https://{.verbatim}, www.{.verbatim},
www2.{.verbatim}, or m.{.verbatim} from the beginning of our url (if
we don't, all urls would end up in the hiv{.verbatim} container,
which is not what we want). This can be done in PostgreSQL or in the
code that submits the url.
So we can do:
select ascii('a') => 97
select ascii('a') in (48, 53, 59, 97) => true
select ascii('a') in (48, 53, 59) => false
This lets us implement the actual constraints in an easy way. We want to
define constraints which only let the defined urls into the defined
table (urls starting with s{.verbatim} in urls_s{.verbatim}, urls
starting with a{.verbatim} or k{.verbatim} in urls_ak{.verbatim}).
The only thing we have to care about is that we have non-overlapping
constraints and that there is no gap in between them. In our case this
means having a table for every possible character that is allowed in a
url. Otherwise, PostgreSQL would not know where to store them.5
(
CHECK (ascii(url) in (115))
) INHERITS (urls);
(
CHECK (ascii(url) in (97, 107))
) INHERITS (urls);
...
Once these constraints are set up, the last thing we need to do6 is set up a trigger function that is being executed by PostgreSQL on every insert query. The purpose of this function is to tell PostgreSQL which table to use. We will use our already-defined constraint-syntax again in order to implement this function7. Trigger functions are being called by PostgreSQL automatically if certain events happen and allow us to modify or change the event in question. In our case we want to modify the table which the data will be inserted in.
RETURNS TRIGGER AS $$
BEGIN
IF (ascii(NEW.url) in (115)) THEN
INSERT INTO urls_s VALUES (NEW.*);
ELSIF (ascii(NEW.url) in (97, 107)) THEN
INSERT INTO urls_ak VALUES (NEW.*);
...
ELSE
RAISE EXCEPTION 'url out of range. Fix the url_insert_trigger() function!';
END IF;
RETURN NULL;
END;
$$
LANGUAGE plpgsql;
Lastly, we need to tell PostgreSQL explicitly to utilize the
url_insert_trigger{.verbatim} function on every insert call on the
urls{.verbatim} master table:
BEFORE INSERT ON urls
FOR EACH ROW EXECUTE PROCEDURE url_insert_trigger;
That's it. We've implemented the partitioning scheme. The next step would be to test it and to see whether it works as expected. Since we already have a list of 8000 urls from our earlier Clojure testing, we can just go ahead and insert these urls into the urls table. Afterwards, we can compare the results of our Clojure grouping with the contents of our PostgreSQL tables.
Testing the Implementation
We will just generate a list of 8000 insert queries and test the result against our grouping. This is quickly done with a simple Clojure function:
Our earlier defined Clojure function 'present-results' also returns a list of entries which we can use to match against the entries in the database tables:
Partition Clojure Database
s 732 732 ak 737 737 bl 734 734 cj 759 759 de 679 679 fg 713 713 hiv 687 687 mr 760 760 np 779 779 txyzo 769 769 uw0123456789q 651 651
And indeed, the values match. With this done, we can say that we implemented a partitioning scheme that works well for a coherent distribution of urls within a database. The next step would be to test this against a simpler one table approach for select and insert operations. Which is something I plan to do in the next couple of days once I have generated more url data.
Just for this example, I doubt that it is possible to assign a city correctly just based on the name, you'd also need a field like the country or GPS position, but I wanted to keep the example simple.
I should note that I did not specifically include foreign domains, which explains the huge difference between .com and the rest
The actual implementation in PostgreSQL would, of course, simply use the ascii values of the first letter, but for the testing in Clojure, using Regexes is simpler
Conveniently, a bigserial on the master table will automatically be handled correctly for sub tables meaning we get proper ids without any hassles.
Also, I should have mapped all allowed characters in a URL as of http://www.netregister.biz/faqit.htm#1
We'll ignore adding proper indexes on the url column for the sake of briefness
This feels like something which PostgreSQL ought to be able to do automatically based on the given constraints, but I could not find out whether this is somehow possible or not. Based on the discussions found here it seems that it is not possible to do that yet.